● Strong's Numbersによる原語テキストの分類
Strong's Numbersとは、James Strong博士(1822-1894)によって執筆された"Exhaustive Concordance of the Bible(1890)"で掲載された、聖書に使われるヘブライ語・ギリシア語の単語の分類コードです。
Strong's Numbersの特徴をあげると以下のようになります。
・単語の語尾変化を含めて語幹(Stem)による統一した分類コードが割り当てられている
・語幹からくる派生語、合成語なども体系的に網羅してまとめている
・単語ごとの文法上の分析は別途付記するようにしている
以下にStrong's Numbersの例をあげます。
ヨハネ1:1のギリシア語本文(ローマ字表記)
John 1:1
en arch hn o logo" kai o logo" hn pro" ton qeon kai qeo" hn o logo"
同上のParsed Text:
「単語 <分類コード> {文法分析}」の順で表記
John 1:1
en <1722> {PREP} arch <746> {N-DSF} hn <2258> <5713> {V-IXI-3S} o <3588> {T-NSM} logo" <3056> {N-NSM} kai <2532> {CONJ} o <3588> {T-NSM} logo" <3056> {N-NSM} hn <2258> <5713> {V-IXI-3S} pro" <4314> {PREP} ton <3588> {T-ASM} qeon <2316> {N-ASM} kai <2532> {CONJ} qeo" <2316> {N-NSM} hn <2258> <5713> {V-IXI-3S} o <3588> {T-NSM} logo" <3056> {N-NSM}
Word <Strong's Numbers> {Grammatical Analysis}
これだけだと記号だらけで何のことやら判らないのですが、これに電子版のコンコルダンス(聖書辞書)を備えたとします。例えば11番目の単語qeonの分類コード<2316>を拾ってStrong's コンコルダンスに流し込むと、以下の結果が出て来ます。
"Exhaustive Concordance of the Bible(1890)"より
2316
theos {theh'-os}
of uncertain affinity; a deity, especially (with <3588>) the supreme Divinity; TDNT - 3:65,322; n m
AV - God 1320, god 13, godly 3, God-ward + 4214 2, misc 5; 1343
(1) a god or goddess, a general name of deities or divinities
(2) the Godhead, trinity
(2a) God the Father, the first person in the trinity
(2b) Christ, the second person of the trinity
(2c) Holy Spirit, the third person in the trinity
(3) spoken of the only and true God
(3a) refers to the things of God
(3b) his counsels, interests, things due to him
(4) whatever can in any respect be likened unto God, or resemble him in any way
また同じ分類コード<2316>が13番目の単語qeo"に出てきますが、語尾変化の違いに関わらず同じ語幹(Stem)で分類しているのがStrong's Numbersの特徴でもあります。ちなみに<2316>の単語使用回数は"AV-"に一覧されていて、全部で1343回、その内の大多数が英語訳では"God"に使われているということが判ります。ここで<2316>を検索をかけると同じ語幹に分類された単語を含む聖書箇所がリストとして出てくることになります。一般の単語検索では綴りが同じものでなければ検索に引っ掛からないので、かなり絞られた検索結果を得ることになります。いわば分類コードは原語の語彙グループを結束する役割を担っていると言えます。
原語に分類コードを振ることの長所
・各単語の語幹を分類コードで識別することで単語の語彙の見通しが立ちやすい
・分類コードを検索すれば単語の使用状態が文章の前後関係を含めて統計的に理解できる
・分類コードを元に各単語の脚注を効率よく提示できる
● 翻訳テキストの分類コード化
上記の>Strong's Numbersに従って分類コードを振った翻訳テキストを"Parsed Text"と言います。
以下にStrong's Numbersによる対訳の例を示します。
上段:King James Version(KJV)のParsed Text
下段:ギリシア語のParsed Text
John 1:1(in English)
In <1722> the beginning <746> was <2258> <5713> the Word <3056>, and <2532> the Word <3056> was <2258> <5713> with <4314> God <2316>, and <2532> the Word <3056> was <2258> <5713> God <2316>.
John 1:1 (in Greek)
en <1722> {PREP} arch <746> {N-DSF} hn <2258> <5713> {V-IXI-3S} o <3588> {T-NSM} logo" <3056> {N-NSM} kai <2532> {CONJ} o <3588> {T-NSM} logo" <3056> {N-NSM} hn <2258> <5713> {V-IXI-3S} pro" <4314> {PREP} ton <3588> {T-ASM} qeon <2316> {N-ASM} kai <2532> {CONJ} qeo" <2316> {N-NSM} hn <2258> <5713> {V-IXI-3S} o <3588> {T-NSM} logo" <3056> {N-NSM}
この場合、分類コードを引き比べることで、あるギリシア語単語がどの英訳単語に相当するかの目安が簡単に付きます。と同時に、英訳同士で全く異なる単語に訳されたときにも分類コードでコンコルダンスを引いたり検索することで、対訳の元の言葉(原語)との照合性が容易に取れることが判ります。いわば分類コードが、ギリシア語やヘブライ語の語彙グループの結束を、異文化の言語においても強力に保持することができると言えるのです。
そしてそれはテキストの電子コード化という作業においても、数字記号による判別化が容易になることにより一層高い役割を果たすこととなります。ユニークなのはStrong's Numbersを羅列しただけでも、コンピューター上では語幹だけの聖書本文が出来上がってしまうということではないでしょうか。ただ各国語の文法上の単語配列が異なるということになります。この「語彙を判別する」という行為がStrong's Numbersによる分析結果の主要な点で、実はそれがコンピューターにも可能なことなのです。
試しに日本語訳でStrong's Numbersを振ってみましょう。
ヨハネ 1:1 (口語訳)
初め<746>に<1722>言<3056>が あった<2258> <5713>。言<3056>は 神<2316>と共に<4314>あった<2258> <5713>。言<3056>は 神<2316>で あった<2258> <5713>。ヨハネ 1:1 (ギュツラフ訳:1837)
ハジマリ<746>ニ<1722> カシコイモノ<3056>ゴザル<2258> <5713>、コノ<3588>カシコイモノ<3056> ゴクラク<2316>トモニ<4314>ゴザル<2258> <5713>、コノ<3588>カシコイモノ<3056>ワ<2258>ゴクラク<2316>。John 1:1 (in Greek)
en <1722> {PREP} arch <746> {N-DSF} hn <2258> <5713> {V-IXI-3S} o <3588> {T-NSM} logo" <3056> {N-NSM} kai <2532> {CONJ} o <3588> {T-NSM} logo" <3056> {N-NSM} hn <2258> <5713> {V-IXI-3S} pro" <4314> {PREP} ton <3588> {T-ASM} qeon <2316> {N-ASM} kai <2532> {CONJ} qeo" <2316> {N-NSM} hn <2258> <5713> {V-IXI-3S} o <3588> {T-NSM} logo" <3056> {N-NSM}
こうして単語ごとに分析コードを振って仕分けしていくと、結果的にギリシア語コンコルダンスができあがるということになるのでしょうか。少なくともあるギリシア語単語がどういうふうに訳されているかは、検索エンジンで容易にリストアップして知ることができます。あるいは補足的に分類コードをコンコルダンスで引いて単語の意味を知ることができます。ここでも重要なのは、日本語において意訳して全く異なる訳語を充てたときでも、原語との対応が容易に識別でき、他の訳出の記録を検索しリストアップすることのできる点です。そこで分類コードでデータベース化された翻訳テキストは、異なる翻訳との間でも共通の分類コードで容易に対照が図れることが判ります。これが翻訳作業のデータベース化の基礎となるように思えるのです。
翻訳テキストに分類コードを振ることの長所
・訳語に分類コードを振ることで原語との対照、識別が一目瞭然となる
・分類コードを検索すれば原語の訳出情況が容易に把握できる
・分類コードを元に各単語の脚注を効率よく提示できる
・意訳、語彙の多様性といった文化的コンテキストも柔軟に統括することができる
● 電子情報化された聖書のプラットフォーム
a.異文化間でのテキスト→コンテキストの補間
日本語では「行間を読む」という行為がまま必要とされますが、聖書から訳される言葉の使用頻度は各国語のなかで大きなばらつきが出るので、訳語から統計的に文脈を知るには限界があります。逆に訳語のばらつきを原語の語彙で統一するのがStrong's Numbersの方法論です。しかしデジタル的な分類コードには、電子情報としての利点とは裏腹に文脈の流れを阻害する欠点があります。
日本における聖書翻訳でこうしたことが問題になったのは、新共同訳の前身である共同訳(1978)の際に取り入れられた動的等価法(Dynamic Equivalent theory)のときでした。動的翻訳とは単語毎の意味をそのまま逐語的に並べるのではなく、言葉として素直に表現できる語彙に入れ替えたり取りまとめてしまう方法です(詳しくはこちらのページで)。それまでリビングバイブルなど動的翻訳を取り入れたものはありましたが、大方の聖書は逐語的翻訳(Verbatim transration)を旨としていました。それは聖書の原語の意味を正確に伝えるということが宣教の継承問題としてあったからです。しかしながら一方では宣教の目的は異国の言葉でも神の福音を伝承することにあります。この異文化における聖書的コンテキストの形成が、逐語的なのか動的なのかの違いを越えた本来の目的なのだと思います。
・優れた翻訳の理想は注釈抜きでそのまま理解できることにある。(しかし完璧な訳はない)
・熟語、慣用表現など、単語vs単語の対応では訳しきれない事柄がある。
・文化的なコンセンサスのない概念や思想の文脈は単語の置き換えだけでは対応不十分である。
・文化的コンテキストの補間のために過去に多くの脚注や注解書の類が出されている。
そもそも聖書の章節の割り振りは注解のために行われたもので、単語に振られた分類コードは脚注のために振られたものと理解できます。そしてミクロとマクロの整合性を取る作業は翻訳という作業に留まらず、聖書を巡る文化全体に関わることだと思います。その伝統のうちテキストで表示されたものに限り、電子化して利便性を高めようというのがここでの趣旨です。
b.オープンソース化された電子コード
面白いことに分類コードは漢字の表記では"JISコード"や"Unicode"が使われており、そもそも漢字自体が「へん」と「つくり」によって語彙グループを形成してきた歴史をもっています。コンピューターで文字を電子コード化するのはフォントセットの表示コマンドとして普通に使われていますが、聖書に限って語彙グループにまで踏み込んでコード化したところがStrong's Numbersのユニークな点と言えるでしょう。すでに1890年に出来上がったStrong's Numbersは事実上のオープンソースとして活用されつつあると言えます。
このように手間暇かけて電子コード化したテキストをどのように使うのかという気もしますが、ソフトウェアについて簡単に例をあげます。
・テキスト・リーダー:電子テキストを表示するソフト
・検索エンジン:電子テキストの要素を検索し合致するものをリストアップするソフト
・辞書機能:単語や文体の意味を表示するソフト
これらを機能を併せ持って本文と連動できるソフトウェアが必要なのですが、さらに重要な点としてデータを追加したりカスタマイズできる機能があると思います。世の中のものはなんでも修正が必要で、聖書原典でさえ一定の期間にメンテナンスを加え、本文の整理に努めています。しかしながら「テキストの連動」と「テキストの更新」ということはソフトウェアの機能上では矛盾していて、結局ソフトウェア全体を更新するということで機能障害を回避する方法がほとんどです。このときのプログラマーの負担は非常に大きく、その分ソフトウェアの価格に跳ね上がってくるということになります。
こうしたときデータの更新と追加がしやすいフォーマット(決まり事)のあるに越したことはありませんが、Strong's Numbersはテキスト間のみならずソフト間の連動を保持するのに便利であると思われます。
・フォーマットが比較的単純(最大5桁の数字)
・日毎に増えていく訳語の多様性を分類コードで一元化して検索できる
・分類コードの語彙グループに従って脚注や辞書を容易に拡張できる
c.データベースの閲覧、コマンドなど
実はこのページの記述方式はHTMLというタグ・コマンドを用いて表示されています。同様にStrong's Numbersや文法分析も、<>や{}でタグ・コマンド化できます。タグ・コマンドはソフトウェア上でテキスト上の表記をコマンド(命令機能)として認識する決まり事で、表示/非表示の他、リンクや強調表示などの機能的な意味をソフトウェア上で持たせることができます。この取り決めの代わりに特別なプログラミング技術がなくとも、簡単なテキスト・ベースの表記だけでソフトウェア上で処理をしてくれるところが便利な点です。
・本文と電子コードとの区別に<>や{}などのカッコ括りや、/、%などの記号で区分する
例:%John@1:1/en <1722> {PREP} arch <746> {N-DSF}/
・アイコンかショートカットで必要なコマンドをソフトウェア上で設定する
例:%、@は非表示、:は節表示、//内は本文表示、<>内は"S"で表示、{}内は"G"で表示など
・その他の辞書、検索などのソフト呼出、実行機能を本文と連携させる
例:"D"で辞書起動、"F"で検索エンジン起動など
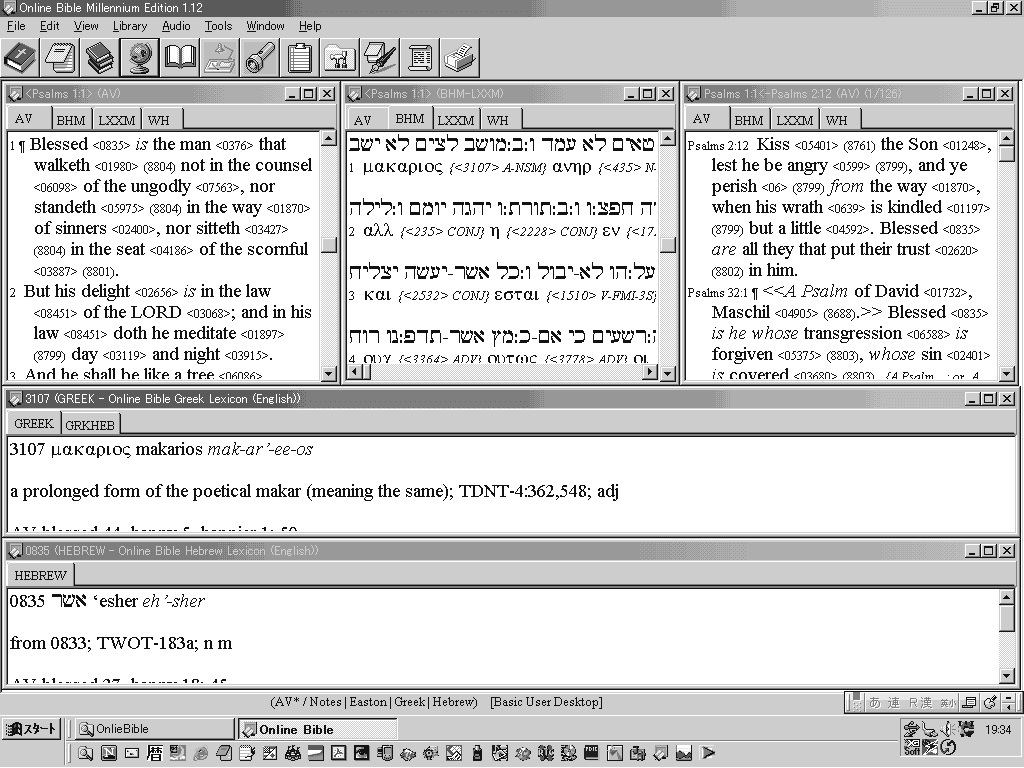
OnlineBibleで提供されるフリーソフト(英語版)
上段)左:KJV Parsed Text 中:BHS & LXX Parsed Text 右:関連聖句
中段)下段)Strong's Concordance(Greek、Hebrew、Greek to Hebrew)
※聖書テキスト、辞書、注解などがテキストデータとして追加できる
d.ユビキタスな聖書コンテンツの策定
ユビキタスとは遍在的などこにでも存在するという意味。多くの人はキリスト教関連図書を聖書以外に多く持っているということになりますが、実際にそれが頭のなかに入っているというよりは、いざ調べ物に使いたいというときに書庫に缶詰になるということがほとんどかと思います。ここではそうした聖書関連の辞書や原語といったものをコンパクトなコンピューターに収めて、どこにでも持って歩こうという趣旨です。
はっきりいって日本語聖書はもとより、ギリシア語聖書のインターリニア(逐語訳)やStrong's Numbers付聖書が、Palm-OSやPocket PCの手帖サイズの端末に収まるということを知って非常に驚くとともに、これまで時間と暇を掛けて行ってきた聖書研究が好きな場所で、人と話ながらでもできるという利点が出てきました。それも小さいからという制限抜きで、本当に幅広く聖書研究が行えるということが判り、驚くほどです。(詳しくは手のひら聖書のススメを参照)
ちなみにPalm-OS機(BibleReader使用)を例にとると表示画面は以下のようになります。
【テキストの閲覧】
→
Strong's Numbers
の選択
【辞書のポップアップ】検索ボタンを押す
↓
【検索画面】
幾つかのオプションが選べる→
単語の検索
【検索結果のリスト】
リストを押すと聖書箇所を表示